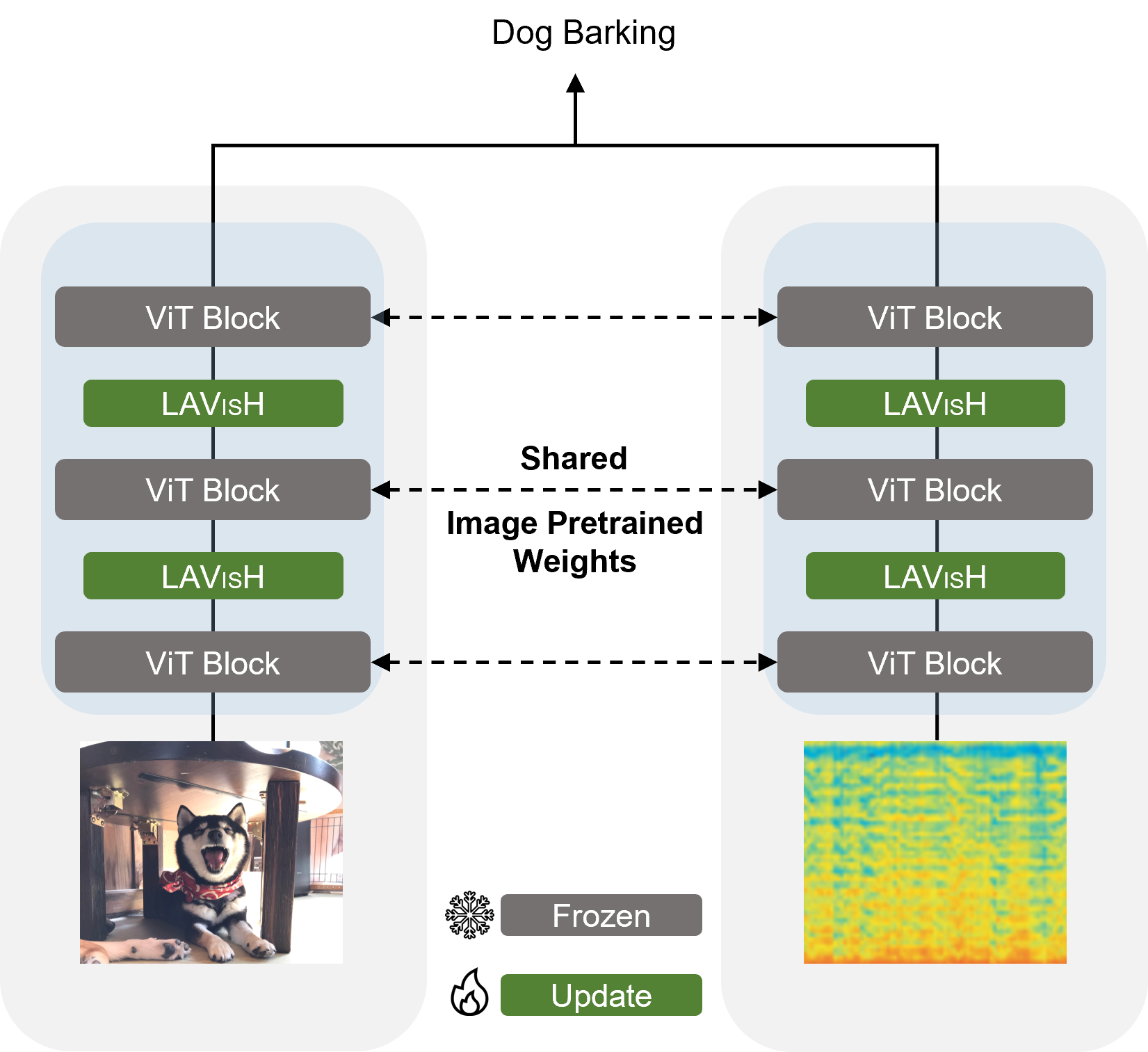
We investigate whether frozen vision transformers (ViTs) pretrained only on visual data can generalize to audio data for complex audio-visual understanding tasks. For this purpose, we introduce a latent audio-visual hybrid adapter (LAVISH), which is inserted into every layer of a frozen ViT model. By tuning only a small number of additional parameters we can enable a pretrained ViT to efficiently (i) adapt to the audio data, and (ii) fuse relevant cues across audio and visual modalities.
Vision transformers (ViTs) have achieved impressive results on various computer vision tasks in the last several years. In this work, we study the capability of frozen ViTs, pretrained only on visual data, to generalize to audio-visual data without finetuning any of its original parameters. To do so, we propose a latent audio-visual hybrid adapter (LAVISH) that adapts pretrained ViTs to audio-visual tasks by injecting a small number of trainable parameters into every layer of a frozen ViT. Our LAVISH adapter enables fusing the information from the visual and audio modalities by updating a small number of additional parameters. To make the fusion between the two modalities efficient, we use a small set of latent tokens, which form an attention bottleneck, thus, eliminating the quadratic cost of standard cross-attention. Compared to the existing modality-specific audio-visual methods, our approach achieves competitive or even better performance on various audio-visual tasks while using fewer tunable parameters and without relying on costly audio pretraining or external audio encoders that might be difficult to transfer to different tasks and domains.
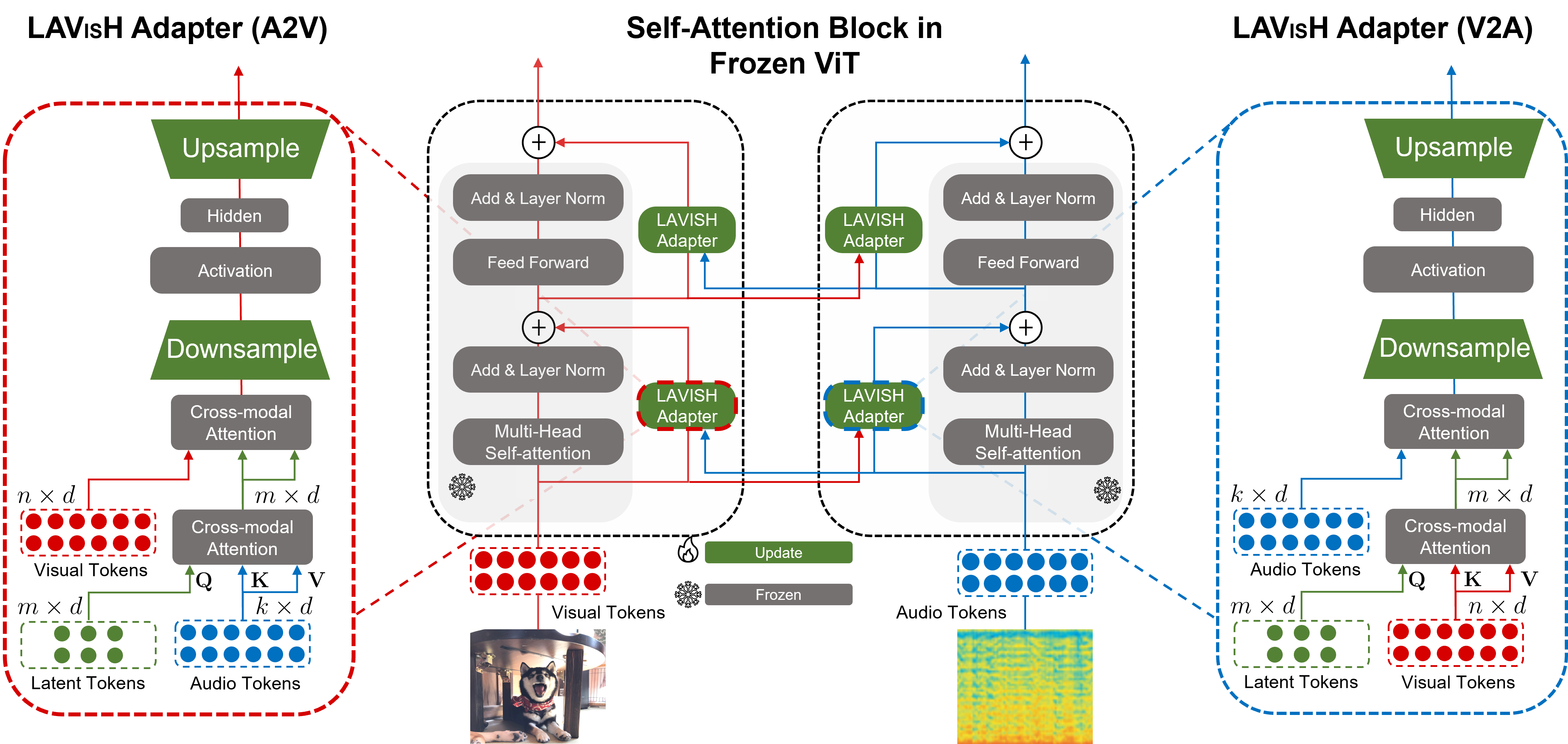
Middle: Our framework consists of a frozen vision transformer (ViT) augmented with trainable latent audio-visual hybrid (LAVISH) adapters between transformer blocks. We use a bi-directional LAVISH adapter that allows us to transfer information from audio to visual tokens, and conversely from visual to audio tokens. Left/Right: Each LAVISH adapter consists of four high-level components. First, we introduce a small number of latent tokens for learning compressed audio or visual representation. Next, the first cross-modal attention operation within the LAVISH module compresses all the tokens from one modality (either audio or visual) into the latent tokens. Afterward, the second cross-modal attention operation performs audio-visual fusion between the latent tokens of one modality (either audio or visual) and the tokens from another modality (visual or audio). Finally, the fused tokens are fed into a lightweight adapter module which computes a more discriminative audio-visual representation and outputs it to the next operation in a ViT layer.

Vision Transformers are Parameter-Efficient Audio-Visual Learners
BibTeX
@InProceedings{LAVISH_CVPR2023,
author = {Lin, Yan-Bo and Sung, Yi-Lin and Lei, Jie and Bansal, Mohit and Bertasius, Gedas},
title = {Vision Transformers are Parameter-Efficient Audio-Visual Learners},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year = {2023}
}